Method
The neural network is set up as shown in the figure below.
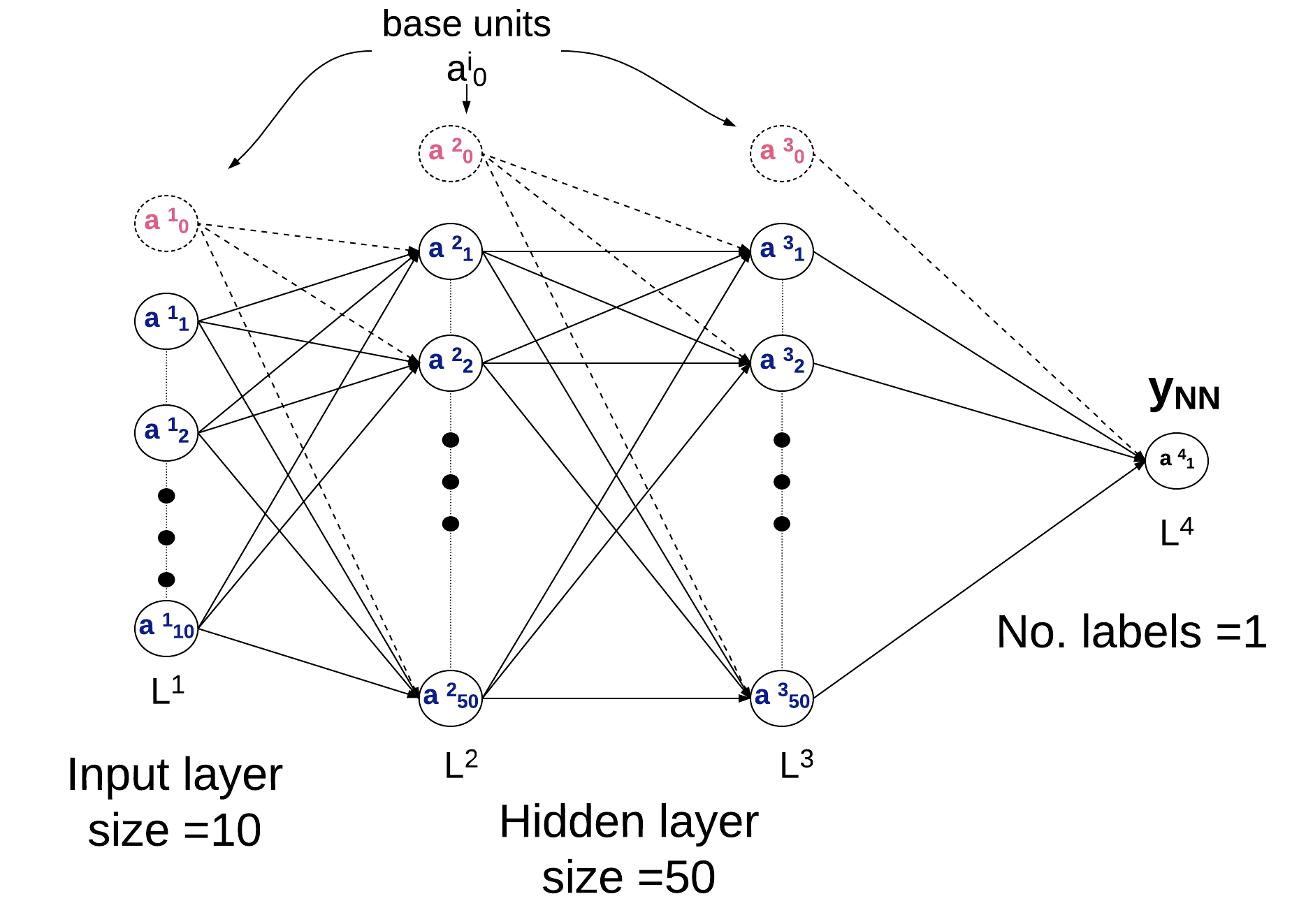
The network is trained on the training set. The procedure is as follows
-
Decide on the input parameters for the data (x), the number of hidden layers and the number of nodes in each hidden layer.
-
Initialise the weights of the network. These will be randomly generated numbers, our starting point. As the network runs these weights become optimised as the neural network learns which information is important to correctly guess the catagory of the object. The weights connect each node in the previous layer to each node in the present layer, thus the weights are a matrix with size ((N layer_i +1) x N layer_j ) where j = i+1. NB there is an extra node added in layer_i which is the zero node or base unit.
-
Using the initial weights, compute how well the network predicts the true outcome. For layers 1 to 4 (i.e input, 2 x hiddenlayers and output) we compute the following (the superscript denotes the layer number):
- Different functions can be used here but we use the cost function to descibe how close our model is to predicting the correct classification. It is defined as
- where m is the number of data points in the sample, L are the total number of layers and
-
To reduce the cost function and train the network we then work backwards (back propagation) to compute the gradient of the cost function which we can feed in our our optimiser inorder for it to search for the Theta parameters that return minimum cost and therefore best model the training data.
- We compute a delta for layers L down to 2.
- The gradient at each layer (l) and each unit (j) in that layer is
-
With the cost function and gradient of cost function algorithm we can now take advantage of built-in optimisation routines in python. I have used the scipy.optimize.fmin_cg function.
-
Now the neural network is set up we can test that the gradients are being computed correctly by running a small sample through our gradient computation routine and comparing the outcome with that from a simple finite difference routine.
-
If that looks good the next step is computing the best regularisation parameter Lambda, and the number of nodes required in the hidden layers using the cross-validation data set.
-
We chose the values of Lambda and the number of hidden layer nodes as those that give the lowest cost-function/highest accuracy on our cross-validation data set.
-
Now we can train the network using these values and see how well it performs on the test data set as a function of the number of iterations required by the optimisation function.
UPDATE: I found that it was more efficient to use the sklearn.neural_network.MLPClassifier. The new code has been added to the repo, and I will be updating the results section.